

In observability work, the request rarely starts with the word governance.
It usually arrives more quietly:
“We would like to standardize collection.”
At first, it sounds like a fairly classic industrialization effort. We talk about the collector, packaging, configuration, destination, deployment method.
As long as the estate is still manageable, that reading mostly holds.
Then the estate grows, teams multiply, exceptions pile up, and the questions change tone.
Who pushed this configuration?
Why is this server not covered?
Why did volumes double since Friday?
Who validates regulatory logs before the audit?
How do we change backend without touching 20,000 machines again?
That is usually when “fleet management” becomes a convenient word for a wider problem.
Keeping the collection estate readable.
Knowing who changed what.
Limiting the blast radius when a configuration moves too fast.
And putting responsibility back where telemetry is produced.
The typical scene
I ran into this topic about six months ago, during an audit for a customer in audience measurement.
The starting point was fairly healthy.
The customer wanted to standardize collection, stay agnostic toward its observability vendor, and avoid putting all telemetry behind a proprietary agent. There was technical leadership, real open source awareness, and a clear desire to avoid being locked in too early.
On paper, this is exactly the kind of context where OpenTelemetry should help.
Except the discussion quickly moved away from the choice of collector.
The collector still mattered, obviously.
It no longer explained why the project was getting stuck.
There was no clear model to charge telemetry back internally. The RACI between platform, security, application teams, and operations was still blurry. Internal IAM did not yet make clean delegation easy. Above all, teams did not really see the cost of what they were producing.
In that context, a cleaner YAML file does not change much.
You can deploy the best collector in the world. If nobody sees the budget, nobody fixes bad telemetry for long.
Volumes go up. Logs get sent twice. Sometimes three times. Labels are added without checking cardinality. Pipelines stay in place because they already exist, even when they no longer serve a purpose.
And when the bill finally explodes, the answer comes quickly:
“That is not our problem. That is the observability team’s problem.”
That is where fleet management starts to mean something else.
Pushing configuration to agents is only one part of it.
You need to make visible who produces what, at what cost, with what quality, and with what responsibility when it breaks.
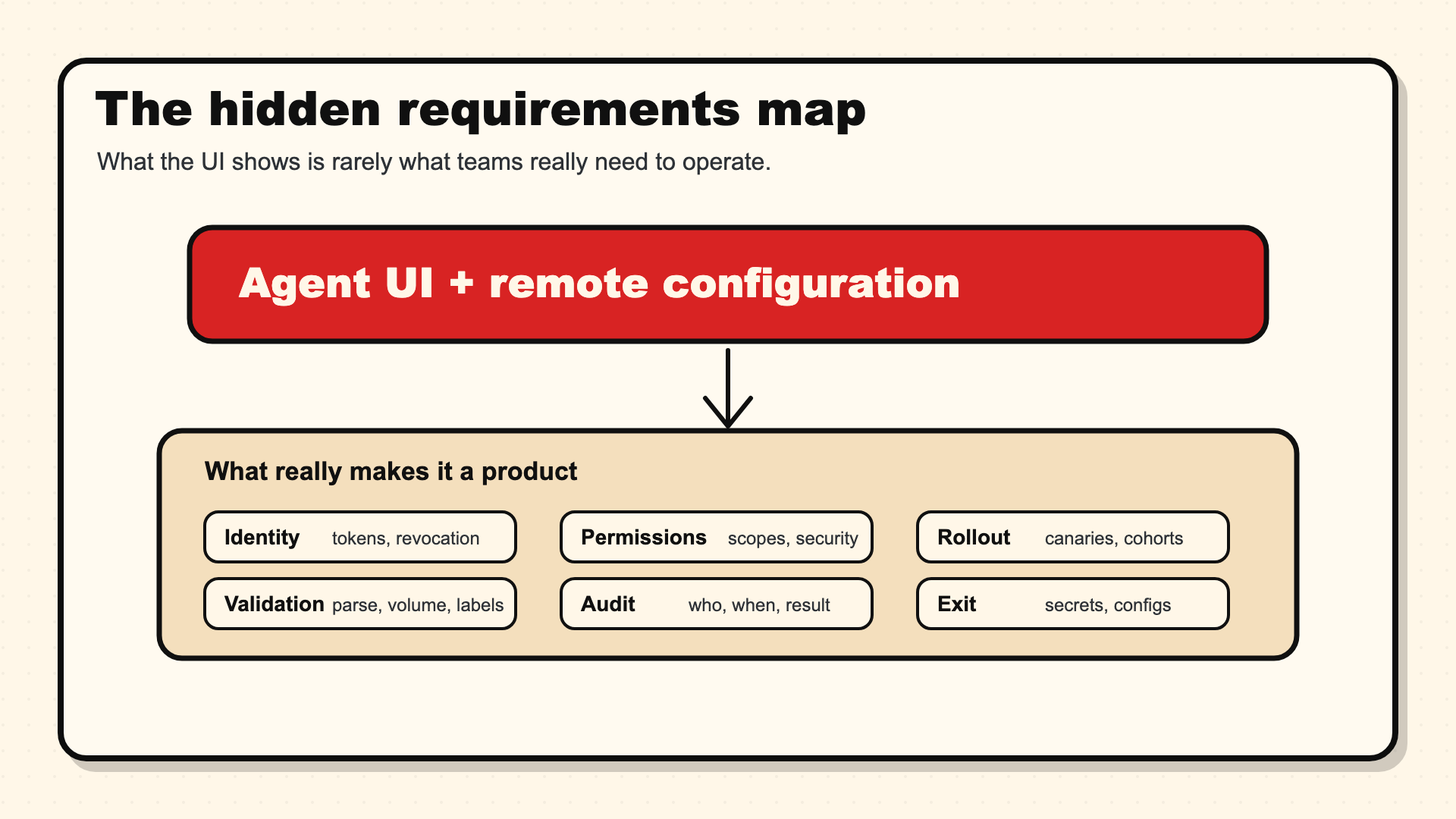
The hidden requirements map
When a customer says “fleet management”, they often picture an interface that shows agents and lets someone push configuration.
That is the visible part.
In workshops, the questions arrive differently.
A machine joins the estate. Who gives it an identity? Which token does it use? How is that token scoped? How is it revoked? How do you avoid keeping a replaced server as a stale duplicate in inventory?
That base may sound administrative, but everything else depends on it.
Then come permissions.
In a large organization, an application team, security, operations, and platform should not have the same level of control over collection. A team needs to act within its own scope without modifying a global pipeline. Security logs are not handled like a normal application stream. A local policy can quickly have a global effect if its boundaries are loose.
Then rollout enters the conversation.
A log configuration can double volumes, break a parser, expose sensitive data, or reduce enough noise to save a budget. So teams ask for canaries, cohorts, rollout rings, holdbacks. The idea is to keep a stopping point before a configuration that works on ten machines has time to break ten thousand servers.
Validation sits in the same area.
Before sending a configuration to an estate, you need to know whether it starts, whether it parses, whether it adds toxic labels, whether it duplicates data, whether it changes a critical destination, whether it changes expected volume. Part of that can be automated. Part of it needs a clear review workflow.
And once the change goes through, the proof remains.
Who changed what, when, on which cohort, with what result, and with which rollback path. For an audit, a security incident, or just a Friday evening where logs disappear, that trace is worth more than a reassuring screenshot.
The last layer is often underestimated: exit.
An observability control plane quickly settles into the way teams work: secrets, generated configs, local services, dashboards, inventories, operating procedures. The day you need to change backend or leave a product, you discover what the platform really owned.
This is the requirements map customers have in mind, even when the first word they use is simply “fleet management”.
Why OpAMP alone is not enough
OpAMP is interesting because it gives us an open base for talking about agent management.
That already matters.
In a market where every vendor has an incentive to pull the estate toward its own agent, a common protocol for reporting state, pushing configuration, managing capabilities, or exchanging credentials changes the discussion.
For a customer, that base still leaves a lot to solve.
Agents need to be enrolled cleanly. They need to appear in a reliable inventory. Teams need to understand which configuration is actually running. Secrets need to be renewed. Rights need to be delegated without opening the whole platform. A configuration needs to be tested before it is sent. Rollouts need rings. Errors need to be readable without digging through three systems. Rollback needs to exist. Proof needs to remain usable.
OpAMP gives part of that loop. The rest lives in the product, the workflows, and the responsibilities built around it.
That is why I am careful with the “OpAMP = exit from lock-in” story.
The reality is more nuanced.
OpAMP can reduce some lock-in risks. It can make part of the control layer more portable. It can prevent the whole agent-control-plane relationship from being trapped inside a proprietary API.
Real portability also depends on everything around the protocol: identity model, secret storage, configuration format, deployment integration, audit, permissions, cleanup on exit.
That is where an OpAMP product can create value.
The useful question is what teams can actually operate with it: permissions, rollouts, audit, understandable errors, rollback, clean exit.
Why proprietary solutions are reassuring
Proprietary agents and control planes did not become popular by accident.
They remove a lot of friction.
You install the agent, it appears in a UI, you push a policy, you see the state of the estate, you open a support ticket when it breaks, and vendor responsibility is easier to read.
For many organizations, that is a rational decision.
The cost of a tool can be lower than the real cost of an underfunded internal platform carried by two people, three Ansible scripts, and documentation nobody wants to touch.
The dependency becomes visible later, when the organization wants room to move again.
Does the configuration remain portable?
Can the identity model survive outside the product?
Can secrets be separated?
Can agents send to multiple destinations?
Can the pipeline be rebuilt outside the UI?
Can the organization exit without losing history, breaking audit, and reinstalling the whole estate?
That is often where you see the real maturity of a fleet-management product.
Onboarding matters, of course.
Exit matters just as much.
The matrix I would use with a buyer
With a Head of Platform, I would start from a simple question: what does the control plane actually take responsibility for?
Does the product stop at agent visibility? Does it also cover enrollment, configuration, rollouts, rollbacks, audit, and secret rotation?
Then I would look at the surrounding capabilities.
Who actually restarts the service? Who pushes the final file? Who validates a configuration before deployment? Who gets the error when an agent refuses to start? Who keeps the trace if the change went through Ansible, Terraform, GitOps, or an internal script?
A UI that displays agent state carries a different weight from a platform that can manage its lifecycle end to end.
The next question is portability.
Exportable OpenTelemetry configuration. Replaceable agent. Modifiable endpoint. Separable secrets. Independent destination. These details are boring during the buying process. They become very concrete the day cost, strategy, or vendor direction changes.
I would also ask about failure.
Bad configuration, unavailable control plane, compromised token, destination outage, reconnect storm, cardinality explosion. A mature product should help limit these scenarios before they become incident-dashboard material.
And I would finish with proof.
After a change, I want to recover three things:
- configuration proof: which version was deployed, by whom, on which cohort;
- coverage proof: which agents received the configuration, which failed, which disappeared from the estate;
- FinOps impact proof: what changed in volumes, cardinality, and expected or observed cost.
That is often more useful than an abstract open source vs proprietary debate.
At that level of reading, the differences become fairly clear: some products show the estate, others help operate it.
What the customer wants to be able to say
In the end, the buyer wants to express one simple sentence.
“I know what is running. I know which configuration is applied. I know who changed it. I know how much it costs. I know which team owns it. I know where it broke. I know how to roll back.”
That ability is what gives fleet management its value.
An interface can make the estate more visible. The real business value is felt when the organization regains control over the telemetry it produces: rights, costs, proof, quality, rollback.
That is what I wanted to verify in the lab.
When a solution says it manages agents, I want to see what it really has under the hood.

An agent visible in a UI is the starting point.
The rest matters more: effective configuration, lifecycle, errors, rollouts, audit, and the dependencies that remain on the platform team.
That is the topic of the next article, where I will show what I was able to benchmark in a lab.