

Dans les missions d’observabilité, la demande arrive rarement avec le mot gouvernance.
Elle arrive plus modestement:
“On voudrait standardiser la collecte.”
Au début, ça ressemble à un chantier d’industrialisation assez classique. On parle collector, packaging, configuration, destination, méthode de déploiement.
Tant que le parc reste maîtrisable, cette lecture suffit à peu près.
Puis le parc grossit, les équipes se multiplient, les exceptions s’accumulent, et les questions changent de ton.
Qui a poussé cette configuration ?
Pourquoi ce serveur n’est pas couvert ?
Pourquoi les volumes ont doublé depuis vendredi ?
Qui valide les logs réglementaires avant l’audit ?
Comment on change de backend sans repasser sur 20 000 machines ?
C’est souvent à ce moment-là que “fleet management” devient un mot pratique pour désigner un problème plus large.
Garder un parc de collecte lisible.
Savoir qui change quoi.
Limiter les dégâts quand une configuration part trop vite.
Et remettre de la responsabilité là où la télémétrie est produite.
La scène typique
J’ai retrouvé ce sujet il y a environ six mois, pendant un audit chez un client dans la mesure d’audience.
Le point de départ était plutôt sain.
Le client voulait standardiser sa collecte, rester agnostique vis-à-vis de son vendor d’observabilité, et éviter de mettre toute la télémétrie derrière un agent propriétaire. Il y avait du leadership technique, une vraie sensibilité open source, et une volonté assez claire de ne pas se retrouver enfermé trop tôt.
Sur le papier, c’est exactement le genre de contexte où OpenTelemetry devrait aider.
Sauf que la discussion a vite quitté le choix du collector.
Le collector restait nécessaire, évidemment.
Mais il ne suffisait plus à expliquer pourquoi le projet coinçait.
Il n’y avait pas de modèle clair pour refacturer la télémétrie en interne. Le RACI entre plateforme, sécurité, applicatif et exploitation restait flou. L’IAM interne ne permettait pas encore de déléguer proprement les droits. Et surtout, les équipes ne voyaient pas vraiment le coût de ce qu’elles produisaient.
Dans ce contexte, un YAML plus propre ne change pas grand-chose.
On peut déployer le meilleur collector du monde, si personne ne voit le budget, personne ne corrige durablement la mauvaise télémétrie.
Les volumes montent. Les logs partent en double. Parfois en triple. Les labels s’ajoutent sans regarder la cardinalité. Des pipelines restent en place parce qu’ils existent déjà, pas parce qu’ils servent encore.
Et quand la facture finit par exploser, la réponse arrive assez vite:
“Ce n’est pas notre problème, c’est celui de l’équipe observabilité.”
C’est là que le fleet management commence à vouloir dire autre chose.
Il ne s’agit plus seulement de pousser une configuration sur des agents.
Il faut rendre visible qui produit quoi, à quel coût, avec quelle qualité, et avec quelle responsabilité quand ça casse.
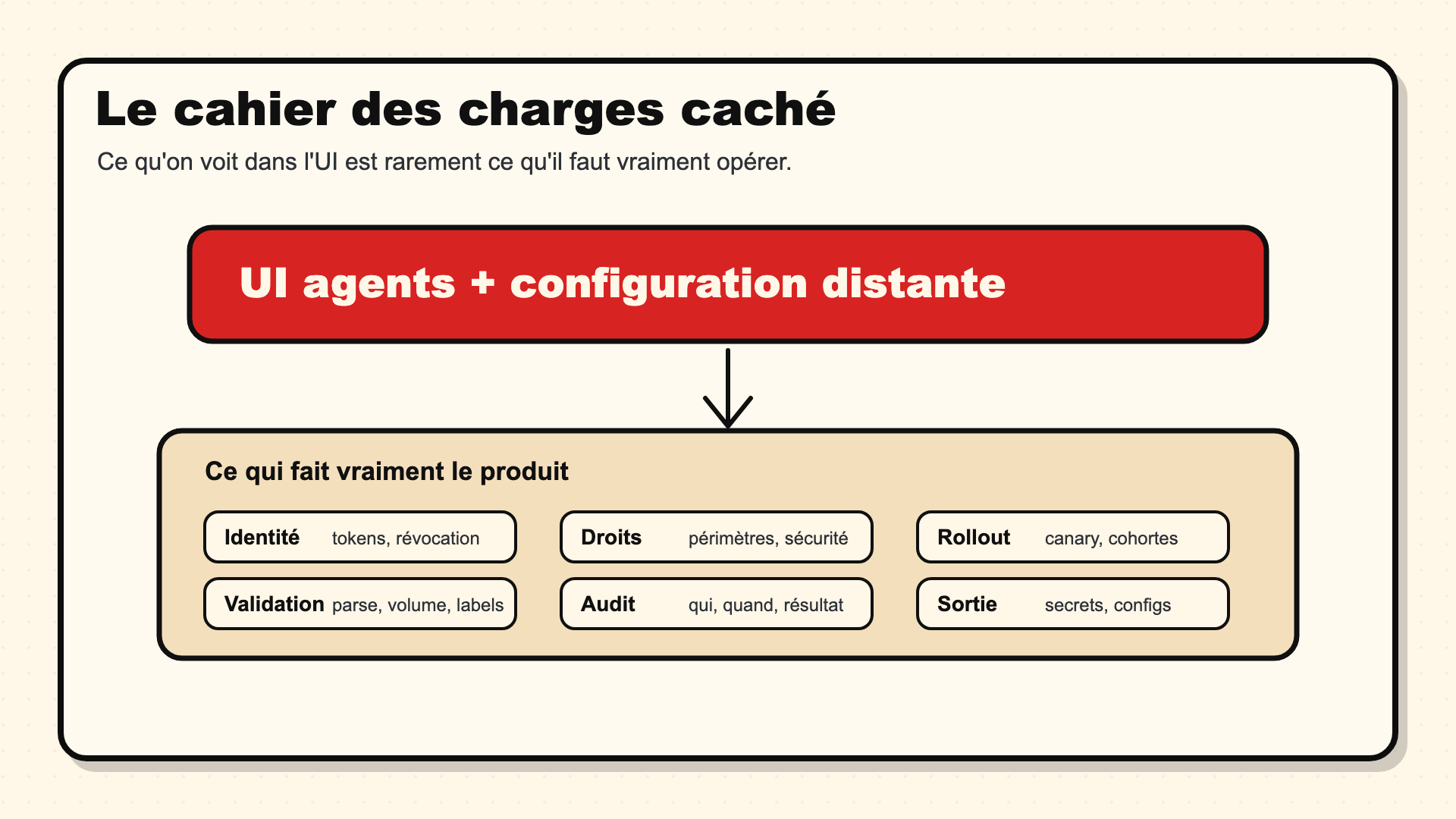
Le cahier des charges caché
Quand un client dit “fleet management”, il pense souvent à une interface qui montre les agents et permet de pousser une configuration.
C’est la partie visible.
En atelier, les questions arrivent autrement.
Une machine rejoint le parc. Qui lui donne son identité ? Quel jeton elle utilise ? Comment on le limite ? Comment on le révoque ? Comment on évite qu’un vieux serveur remplacé reste comme doublon dans l’inventaire ?
Cette base a l’air administrative, mais elle conditionne tout le reste.
Ensuite viennent les droits.
Dans une grande organisation, une équipe applicative, la sécurité, l’exploitation et la plateforme ne doivent pas avoir le même pouvoir sur la collecte. Une équipe doit pouvoir agir sur son périmètre sans modifier un pipeline global. Les logs de sécurité ne se manipulent pas comme un flux applicatif classique. Et une policy locale peut vite avoir un effet global si elle est mal cadrée.
Puis arrive le rollout.
Une configuration de logs peut doubler les volumes, casser un parser, exposer une donnée sensible, ou réduire suffisamment le bruit pour sauver un budget. Donc on veut des canaries, des cohortes, des anneaux de déploiement, des holdbacks. L’idée est de garder un point d’arrêt avant qu’une configuration correcte sur dix machines ait le temps de casser dix mille serveurs.
La validation arrive au même endroit.
Avant d’envoyer une configuration à un parc, il faut savoir si elle démarre, si elle parse, si elle ajoute des labels toxiques, si elle duplique les données, si elle change une destination critique, si elle modifie le volume attendu. Une partie peut être automatisée. Une autre demande un workflow de revue clair.
Et quand le changement passe, il reste la preuve.
Qui a changé quoi, quand, sur quelle cohorte, avec quel résultat, et avec quel chemin de rollback. Pour un audit, un incident sécurité, ou simplement un vendredi soir où les logs disparaissent, cette trace vaut plus qu’une capture d’écran rassurante.
La dernière couche, souvent sous-estimée, c’est la sortie.
Un control plane d’observabilité s’installe vite dans les habitudes: secrets, configs générées, services locaux, dashboards, inventaires, procédures d’exploitation. Le jour où il faut changer de backend ou sortir d’un produit, on découvre ce que la plateforme possédait vraiment.
C’est ce cahier des charges-là que les clients ont en tête, même quand le premier mot utilisé est seulement “fleet management”.
Pourquoi OpAMP seul ne suffit pas
OpAMP est intéressant parce qu’il donne une base ouverte pour parler de management d’agents.
C’est déjà beaucoup.
Dans un marché où chaque vendor a intérêt à ramener le parc vers son propre agent, avoir un protocole commun pour remonter l’état, pousser une configuration, gérer des capacités ou échanger des credentials change la discussion.
Mais chez un client, cette base ne répond pas encore à toute la question.
Il faut savoir enrôler les agents proprement. Les voir dans un inventaire fiable. Comprendre quelle configuration tourne vraiment. Renouveler les secrets. Déléguer les droits sans ouvrir toute la plateforme. Tester une configuration avant de l’envoyer. Déployer par anneaux. Lire les erreurs sans fouiller trois systèmes. Revenir en arrière. Garder une preuve exploitable.
OpAMP donne une partie de la boucle. Le reste se joue dans le produit, les workflows et les responsabilités qu’on construit autour.
C’est pour ça que je me méfie un peu du discours “OpAMP = sortie du lock-in”.
La réalité est plus nuancée.
OpAMP peut réduire certains risques de verrouillage. Il peut rendre une partie du contrôle plus portable. Il peut éviter que toute la relation agent-control plane soit enfermée dans une API propriétaire.
Mais la portabilité réelle dépend aussi de tout ce qui entoure le protocole: modèle d’identité, stockage des secrets, format des configurations, intégration au déploiement, audit, permissions, nettoyage à la sortie.
C’est là qu’un produit OpAMP peut avoir de la valeur.
Le protocole ne suffit pas. Ce qui compte, c’est ce qu’on arrive à opérer avec: droits, rollouts, audit, erreurs compréhensibles, rollback, sortie propre.
Pourquoi les solutions propriétaires rassurent
Les agents et plans de contrôle propriétaires ne se sont pas imposés par hasard.
Ils retirent beaucoup de friction.
On installe l’agent, il apparaît dans une UI, on pousse une policy, on voit l’état du parc, on ouvre un ticket support quand ça casse, et la responsabilité vendor est plus lisible.
Dans beaucoup d’organisations, c’est une décision rationnelle.
Le coût d’un outil peut être inférieur au coût réel d’une plateforme interne mal financée, portée par deux personnes, avec trois scripts Ansible et une documentation que personne n’ose toucher.
La dépendance se voit surtout plus tard, quand l’organisation veut reprendre de la marge de manoeuvre.
Est-ce que la configuration reste portable ?
Est-ce que le modèle d’identité peut survivre hors du produit ?
Est-ce que les secrets sont séparables ?
Est-ce que les agents peuvent envoyer vers plusieurs destinations ?
Est-ce qu’on peut reconstruire le pipeline hors de l’UI ?
Est-ce qu’on peut sortir sans perdre l’historique, sans casser l’audit, et sans réinstaller tout le parc ?
C’est souvent là qu’on voit la maturité réelle d’un produit de fleet management.
L’onboarding compte, bien sûr.
Mais la sortie compte autant.
La matrice que j’utiliserais avec un acheteur
Avec un Head of Platform, je partirais d’une question assez simple: qu’est-ce que le control plane prend vraiment en charge ?
Est-ce qu’il voit seulement les agents dans une UI, ou est-ce qu’il couvre aussi l’enrollment, la configuration, les rollouts, les rollbacks, l’audit et la rotation des secrets ?
Ensuite, je regarderais les fonctionnalités autour.
Qui redémarre réellement le service ? Qui pousse le fichier final ? Qui valide une configuration avant déploiement ? Qui récupère l’erreur quand un agent refuse de démarrer ? Qui garde la trace si le changement est fait via Ansible, Terraform, GitOps ou un script interne ?
Une UI qui affiche l’état d’un agent n’a pas le même poids qu’une plateforme qui sait gérer son lifecycle de bout en bout.
La question suivante, c’est la portabilité.
Configuration OpenTelemetry exportable. Agent remplaçable. Endpoint modifiable. Secrets séparables. Destination indépendante. Ce sont des détails assez ennuyeux au moment de l’achat, mais ils deviennent très concrets le jour où le coût, la stratégie ou le vendor change.
Je poserais aussi la question de la panne.
Mauvaise configuration, control plane indisponible, token compromis, destination qui tombe, tempête de reconnexion, explosion de cardinalité. Un produit mature doit aider à limiter ces scénarios avant qu’ils finissent dans le dashboard d’incident.
Et je finirais par la preuve.
Après un changement, je veux pouvoir retrouver trois choses:
- la preuve de configuration: quelle version a été déployée, par qui, sur quelle cohorte;
- la preuve de couverture: quels agents ont reçu la configuration, lesquels ont échoué, lesquels ont disparu du parc;
- la preuve d’impact FinOps: ce qui a changé sur les volumes, la cardinalité et le coût attendu ou observé.
C’est souvent plus utile qu’un débat abstrait entre open source et propriétaire.
À ce niveau de lecture, les différences deviennent assez nettes: certains produits affichent le parc, d’autres aident vraiment à l’opérer.
Ce que le client veut pouvoir dire
À la fin, l’acheteur veut pouvoir exprimer une phrase simple.
“Je sais ce qui tourne. Je sais quelle configuration est appliquée. Je sais qui l’a changée. Je sais combien ça coûte. Je sais quelle équipe en est responsable. Je sais où ça a cassé. Je sais revenir en arrière.”
C’est cette capacité qui donne de la valeur au fleet management.
Une interface peut rendre le parc plus visible. La vraie valeur business est perçue quand l’organisation reprend la main sur la télémétrie produite: droits, coûts, preuves, qualité, rollback.
C’est ce que je voulais vérifier dans le lab.
Quand une solution dit gérer des agents, je veux voir ce qu’elle a dans le ventre.

L’agent visible dans une UI, c’est le début.
Le reste compte plus: configuration effective, lifecycle, erreurs, rollouts, audit, dépendances qui restent sur l’équipe plateforme.
Et ça, c’est le sujet de l’article suivant, où j’exposerai ce que j’ai pu benchmarker dans un lab.