

When we talk about observability agents, the conversation often starts with the choice of agent. OpenTelemetry Collector, proprietary agent, vendor distribution, sidecar, daemonset, appliance, homemade binary. The debate quickly moves to performance, receivers, exporters, ingestion cost or Kubernetes support.
But in a large fleet, the real question rarely remains only: which agent should we install?
It becomes: who really controls the fleet that produces logs, metrics and traces?
Past a certain volume, installation is no longer the topic. The topic is inventory, configuration, deployment, rollback, security, compliance evidence and the ability to know what is actually running somewhere in the information system. In short: fleet management.
In the OpenTelemetry ecosystem, one name comes up often when remote Collector control is discussed: OpAMP, the Open Agent Management Protocol.
The protocol promises something very attractive: a standard channel to manage agents remotely. Receive their state. Push configuration. See their capabilities. Report errors. Supervise the lifecycle of a fleet.
Put that way, you might think everyone is already using it in production and that the market has aligned around an obvious standard. Looking at products, documentation and public announcements, the reality is more interesting.

Separating real evidence from pretty promises
I wanted to answer a simple question: who is really using OpAMP to manage agents?
Not who mentions OpenTelemetry on a marketing page. Not who says “fleet management” on a slide. Not who offers a UI to configure proprietary agents. Who actually documents an OpAMP integration, a control loop, or usable compatibility?
The nuance matters, because the term fleet management covers several realities.
It can mean an agent inventory. It can mean a console that pushes configuration. It can mean a proprietary agent with its proprietary backend. It can mean an OpenTelemetry Collector distribution packaged with a management layer. It can mean an interface that generates configuration without remotely controlling the agent.
And it can also mean a real control loop based on OpAMP.
When you read quickly, everything looks close. When you have to buy, integrate or recommend a solution, these differences become very concrete.
OpAMP: a promising standard, not yet a market reflex
OpAMP is indeed an OpenTelemetry standard. It defines a protocol for agent management. It covers capability reporting, state reporting, configuration messages, packages, errors and identity information.
On paper, it is exactly what is needed to avoid every vendor reinventing its own control channel.
In practice, the protocol is still young in public usage. The specification exists. The OpenTelemetry Collector extension exists in opentelemetry-collector-contrib. Demos exist. Products use or expose it. But the ecosystem does not yet feel like a massively adopted, mundane standard.
That is not necessarily a problem. Infrastructure standards often mature this way. First a technical promise. Then reference implementations. Then a few products. Finally, if the field pressure is strong enough, a buying and architecture reflex.
For now, OpAMP mostly looks like a signal: the community has identified the agent management problem, but the market has not yet converged on a single experience.
Bindplane: the most tangible example
Bindplane is probably the most visible example when looking for fleet management around OpenTelemetry.
The product emphasizes OpenTelemetry Collector management, inventory, configurations, destinations, sources, processors and deployments. More importantly, the documentation explicitly mentions OpAMP for the Bindplane OTel Collector.
So this is not just a vague compatibility promise. There is documentation connecting the collector, the Bindplane server and OpAMP.
The other interesting point is Dynatrace acquiring Bindplane. That sends a fairly clear market signal: OpenTelemetry agent fleet management is not a side topic. A major observability player considered it useful to buy a specialized piece of that problem.
It does not prove that everyone uses OpAMP. It proves that the business need exists.
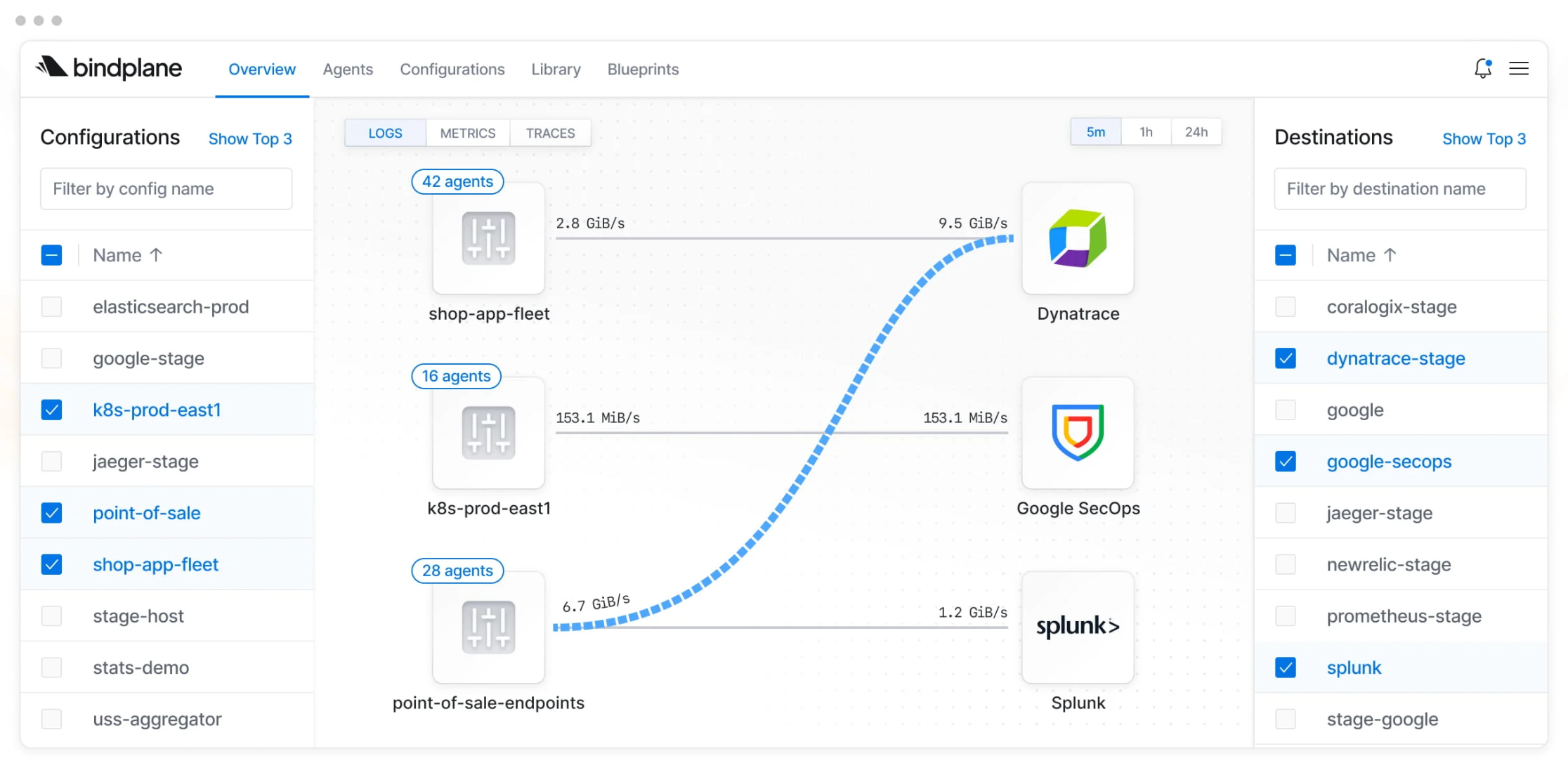
OpenLIT Fleet Hub: the agentic case
OpenLIT is interesting because the topic is not only traditional observability. The tool also targets LLM workloads and observability for agentic systems.
Its documentation presents a Fleet Hub used to manage OpenTelemetry agents. That matches a trend I see emerging: the more agentic architectures spread, the more we will need to control the collectors and agents monitoring those systems.
We do not only want to trace an AI agent. We also want to know who deploys the tracing configuration, who can change it, how those changes are audited and how we avoid every team wiring its own plumbing in a corner.
Fleet management then becomes a governance topic, not only a tooling topic.
Elastic: Fleet exists, but the OpenTelemetry story is subtle
Elastic already has a mature Fleet concept in its own world. Elastic Agent, Fleet Server, policies, integrations: the model is known.
What interested me here was the OpenTelemetry Collector part. Elastic documents adding an OTel Collector in Fleet. That shows a willingness to integrate OpenTelemetry into an existing management environment.
But the reading needs care. Fleet at Elastic is not simply synonymous with OpAMP. Elastic has its own historic management model. The OpenTelemetry integration can answer a very real need without meaning that the whole control loop is based on OpAMP.
That is exactly the nuance to keep when benchmarking solutions: the word Fleet is there, the user experience is there, but the control protocol and the level of standardization are not always the same.
Grafana: architecture matters as much as the interface
Grafana Cloud also documents a Fleet Management offer. Again, the topic goes beyond simple configuration generation.
What interests me in Grafana’s documentation is the architecture. When a vendor explains how agents connect, how fleets are modeled and how communication is secured, we start having material to reason with.
A nice “deploy” button is not enough. In a real information system, you have to answer less glamorous questions.
Who pushed this configuration? Over which scope? With what validation? How do we roll back? What is the source of truth? Can the agent keep running if the control plane is unavailable? Where are secrets stored? How are control-plane privileges limited?
That is where fleet management becomes a real architecture topic.
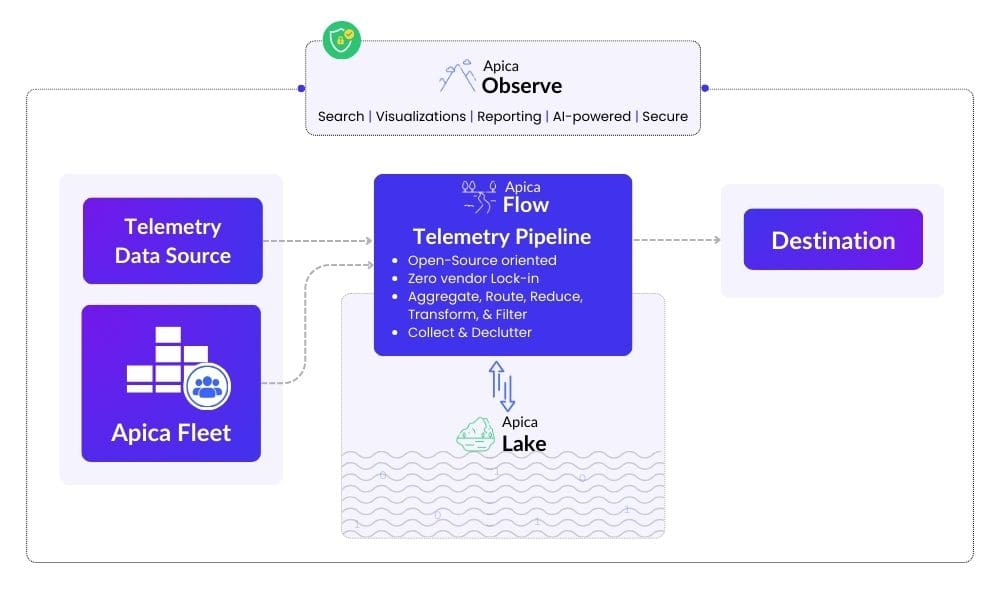
Apica: another reading of the fleet
Apica also documents a Fleet Management approach in its observability ecosystem.
Here again, the need is identified: manage agents and collectors remotely, organize configurations, provide visibility into what is deployed.
What seems important to me is that several actors converge on the same problem without immediately converging on the same implementation. That is typical of a market that knows an irritant exists but has not stabilized its operational standard yet.
For a customer, it means asking “do you have fleet management?” is not enough. You need to ask: which agent, which protocol, which architecture, which experience and which tooling for my platform teams?
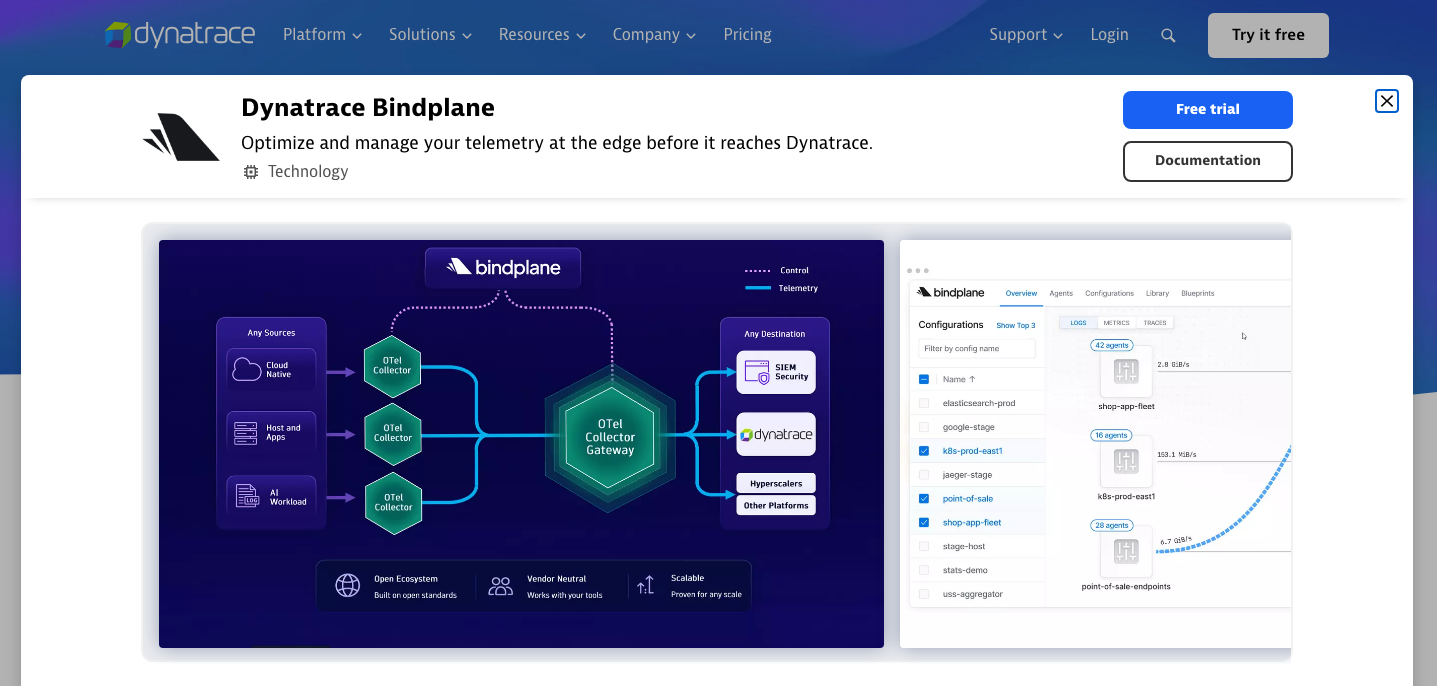
Dynatrace and Bindplane: the acquisition signal
Dynatrace acquiring Bindplane is probably one of the strongest signals.
Dynatrace already has its own agent and its own monitoring universe. Buying Bindplane recognizes that OpenTelemetry and heterogeneous collector management are becoming strategic.
Several things can be read from it.
First, customers want to keep some openness. They do not necessarily want all telemetry to go through a single proprietary agent.
Then, large accounts already have heterogeneous fleets. Even when a vendor is very present, it must compose with different teams, clouds, clusters and legacy systems.
Finally, the battle is not only about collection. It is about the control plane.
Whoever helps manage the fleet becomes the one who sees the inventory, pushes configurations, structures data routes and influences architecture choices.
Category inventory
After this tour, I would classify actors into several categories.
First category: products that explicitly document a relationship with OpAMP or OpenTelemetry Collector management close to the protocol. Bindplane is the main example.
Second category: platforms that provide a fleet management experience for their agents or collectors, with a more or less open OpenTelemetry integration. Elastic and Grafana fall into this zone depending on usage.
Third category: solutions that answer visibility or configuration needs, but where fleet management may describe a more limited or more proprietary experience.
Fourth category: demos, prototypes and community implementations that prove the protocol is usable, but are not necessarily enterprise products ready to carry responsibility for a large fleet.
This classification is more useful than a list of logos. It helps ask the right questions before choosing.
Why large accounts buy more than a protocol
I had in mind an energy customer case, with a tender around fifteen million euros.
At that scale, nobody buys a protocol because it is elegant. Teams buy risk reduction.
They want to know how to deploy without breaking production. How to separate responsibilities between the observability team, platform teams, security teams, operators and application teams. How to trace changes. How to prove that a configuration was applied. How to limit blast radius. How to manage exceptions.
The protocol matters, but it is only part of the answer.
The real value of a fleet management solution is its ability to make these operations governable.
The painful RACI questions
When fleet management is discussed, RACI questions arrive quickly.
Who owns the default configuration?
Who validates telemetry pipelines?
Who can activate a sensitive receiver?
Who authorizes export to a new destination?
Who carries ingestion cost if a team enables too many logs?
Who intervenes when a collector starts dropping data?
Who decides the rollback?
Who audits changes?
Who revokes generated or reused secrets?
These questions sound administrative, but they decide adoption. A solution that ignores these frictions can be technically good and politically impossible to deploy.
What customers really buy
Customers do not only buy “OpAMP”. They buy a way to make observability operable at scale.
They buy a console to see.
They buy an API to automate.
They buy a permissions model.
They buy a rollback story.
They buy an integration with their GitOps, ITSM or security practices.
They also buy the ability to explain the system to teams that do not live in OpenTelemetry every day.
That is where the gap grows between a good technical brick and a good enterprise offer.
Where OpAMP becomes interesting
OpAMP becomes interesting when it helps avoid two dead ends.
The first dead end is all-proprietary. Each vendor manages its agent in its own way, with its backend, format and rules, and the customer loses the ability to reason on a common model.
The second dead end is local bricolage. Each team deploys its collector with its YAML files, conventions and scripts. At small scale, it works. At large scale, it becomes operational debt.
A standard protocol can create a common language between agents, collectors, control planes and internal platforms.
But for that promise to hold, it needs solid implementations, administration tools, security models and field feedback.

Why I ran this lab
I started this lab because I saw many conversations about OpenTelemetry, but few concrete discussions about controlling agents.
Everyone wants traces, metrics and logs. Few people want to face the question of the fleet that produces them.
Yet this is often where observability projects get stuck. Not in theory. In the details: packaging, configuration, secrets, permissions, rollback, inventory, versioning, support, cost, ownership.
So I wanted to leave the abstract debate and look at who documents what.
The wrong benchmark
The wrong benchmark would be asking: which product has the best UI?
UI matters, of course. A clear interface reduces friction. Bindplane, for example, gives a strong impression of a product designed for usage.
But the real benchmark must go lower.
You have to look at the control model, protocols, configuration persistence, guarantees, degraded modes, CI/CD integration, security, audit and the ability to live inside an information system that is never clean.
You also have to look at what is publicly documented. A commercial promise without usable documentation does not carry the same weight as a detailed integration guide.
My starting point
My starting point is simple: OpAMP is an important piece, but not a magic wand.
The market is still stabilizing how to manage OpenTelemetry agents at large scale. Some actors are moving fast. Others already have robust proprietary systems. Others document promising bricks.
To choose, two reflexes should be avoided.
The first reflex is believing that a standard is enough.
The second is believing that a console is enough.
You need both, plus the operational architecture around them.
Sources
- Dynatrace to Acquire Bindplane
- Dynatrace Bindplane Hub
- Bindplane OpAMP documentation
- OpenLIT Fleet Hub documentation
- Elastic: Add an OTel Collector in Fleet
- OpenTelemetry Collector contrib OpAMP extension
- Apica: Fleet Management in OpenTelemetry
- Apica Fleet Management overview
- Grafana Fleet Management
- Grafana Fleet Management architecture
- OpAMP specification