

Quand on parle d’agents d’observabilité, on parle souvent du choix de l’agent. OpenTelemetry Collector, agent propriétaire, distribution vendor, sidecar, daemonset, appliance, binaire maison. Le débat part vite sur la performance, les receivers, les exporters, le coût d’ingestion ou le support Kubernetes.
Mais dans un grand parc, la vraie question finit rarement par être seulement: quel agent installer ?
Elle devient plutôt: qui contrôle vraiment le parc qui produit les logs, métriques et traces ?
À partir d’un certain volume, le sujet n’est plus l’installation. C’est l’inventaire, la configuration, le déploiement, le rollback, la sécurité, la preuve de conformité et la capacité à savoir ce qui tourne vraiment quelque part dans le SI. En clair: le fleet management.
Dans l’écosystème OpenTelemetry, un nom revient souvent dès qu’on parle de pilotage à distance du Collector: OpAMP, pour Open Agent Management Protocol.
Le protocole promet une chose très séduisante: donner un canal standard pour gérer des agents à distance. Recevoir leur état. Leur pousser une configuration. Voir leurs capacités. Remonter des erreurs. Superviser le cycle de vie d’une flotte.
Dit comme ça, on pourrait croire que tout le monde l’utilise déjà en production et que le marché s’est aligné autour d’un standard évident. En regardant les produits, la documentation et les annonces publiques, la réalité est plus intéressante.

Trier les vraies preuves des jolies promesses
J’ai voulu répondre à une question simple: qui utilise vraiment OpAMP pour gérer ses agents ?
Pas qui cite OpenTelemetry dans une page marketing. Pas qui dit “fleet management” dans une slide. Pas qui propose une UI de configuration d’agents propriétaires. Qui documente réellement une intégration OpAMP, une boucle de contrôle ou une compatibilité exploitable ?
La nuance est importante, parce que le mot fleet management recouvre plusieurs réalités.
Il peut désigner un inventaire d’agents. Il peut désigner une console qui pousse une configuration. Il peut désigner un agent propriétaire avec son backend propriétaire. Il peut désigner une distribution OpenTelemetry Collector packagée avec une couche de management. Il peut désigner une interface qui permet de générer une configuration, sans piloter l’agent à distance.
Et il peut aussi désigner une vraie boucle de contrôle basée sur OpAMP.
Quand on lit rapidement, tout semble proche. Quand on doit acheter, intégrer ou recommander une solution, ces différences deviennent très concrètes.
OpAMP: le standard prometteur, pas encore le réflexe de marché
OpAMP est bien un standard OpenTelemetry. Il définit un protocole pour la gestion d’agents. Il couvre notamment la description des capacités, la remontée d’état, les messages de configuration, les packages, les erreurs et les informations d’identité.
Sur le papier, c’est exactement ce qu’il faut pour éviter que chaque vendor réinvente son propre canal de pilotage.
Dans la pratique, le protocole reste encore jeune dans l’usage public. La spécification existe. L’extension côté OpenTelemetry Collector existe dans opentelemetry-collector-contrib. Des démos existent. Des produits l’utilisent ou l’exposent. Mais l’écosystème ne donne pas encore l’impression d’un standard massivement adopté et banal.
Ce n’est pas forcément un problème. C’est souvent comme ça que les standards d’infrastructure mûrissent. D’abord une promesse technique. Ensuite des implémentations de référence. Puis quelques produits. Enfin, si la pression terrain est suffisante, un réflexe d’achat et d’architecture.
Pour l’instant, OpAMP semble surtout être un signal: la communauté a identifié le problème de management des agents, mais le marché n’a pas encore convergé sur une expérience unique.
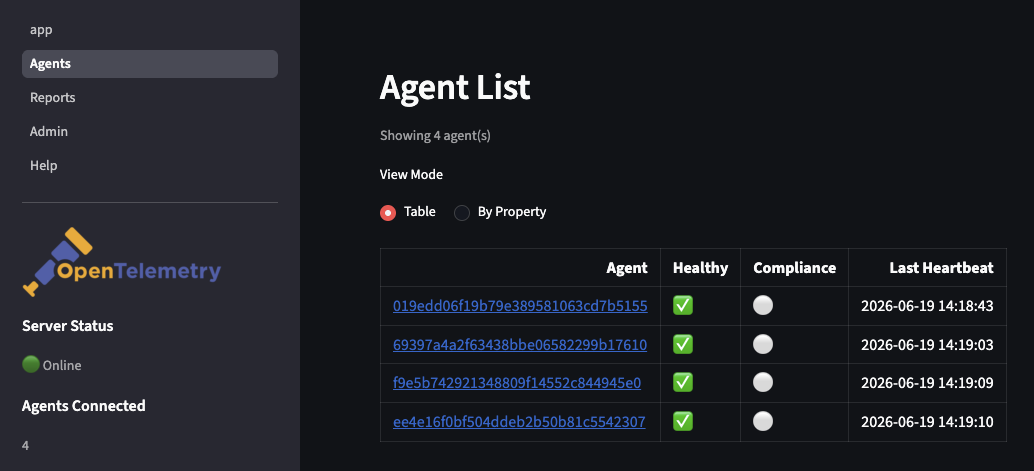
Bindplane: l’exemple le plus tangible
Bindplane est probablement l’exemple le plus visible quand on cherche une solution de fleet management autour d’OpenTelemetry.
Le produit met en avant la gestion des OpenTelemetry Collectors, l’inventaire, les configurations, les destinations, les sources, les processeurs et les déploiements. Surtout, la documentation parle explicitement d’OpAMP pour le Bindplane OTel Collector.
On n’est donc pas seulement dans une promesse de compatibilité vague. Il y a une documentation qui relie le collector, le serveur Bindplane et OpAMP.
L’autre élément intéressant, c’est l’acquisition de Bindplane par Dynatrace. Elle envoie un signal marché assez net: la gestion de flotte d’agents OpenTelemetry n’est pas un sujet secondaire. Un acteur important de l’observabilité a jugé utile d’acheter une brique spécialisée sur ce problème.
Ce n’est pas une preuve que tout le monde utilise OpAMP. C’est une preuve que le besoin business existe.
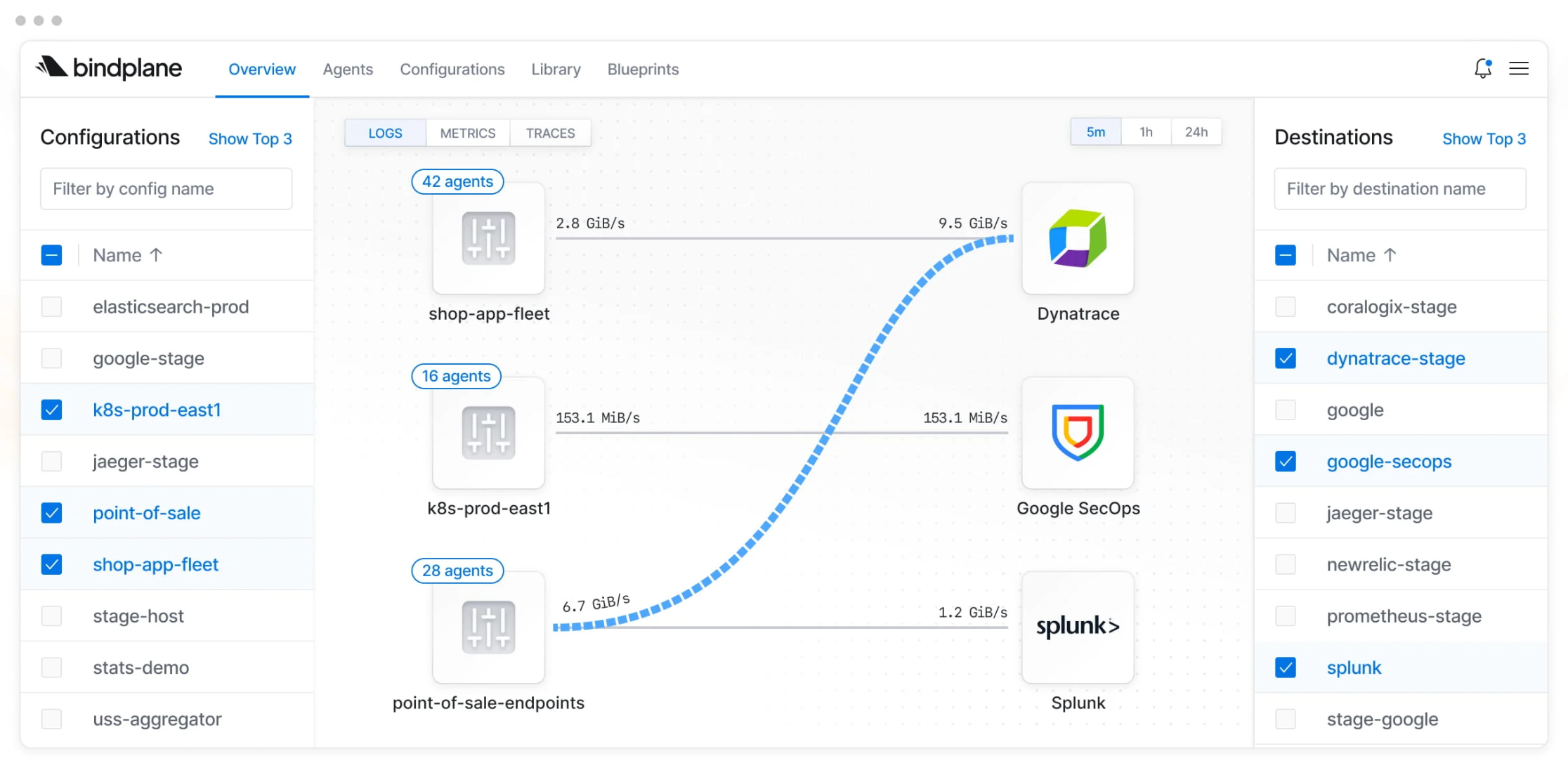
OpenLIT Fleet Hub: le cas agentique
OpenLIT est intéressant parce que le sujet n’est pas seulement l’observabilité traditionnelle. L’outil vise aussi les workloads LLM et l’observabilité de systèmes agentiques.
Sa documentation présente un Fleet Hub qui sert à gérer des agents OpenTelemetry. C’est cohérent avec une tendance que je vois émerger: plus les architectures agentiques se multiplient, plus on va avoir besoin de contrôler les collecteurs et les agents qui surveillent ces systèmes.
On ne veut pas seulement tracer un agent IA. On veut aussi savoir qui déploie la configuration de tracing, qui peut la changer, comment on audite ces changements et comment on évite que chaque équipe branche sa propre tuyauterie dans son coin.
Le fleet management devient alors un sujet de gouvernance, pas seulement un sujet d’outillage.
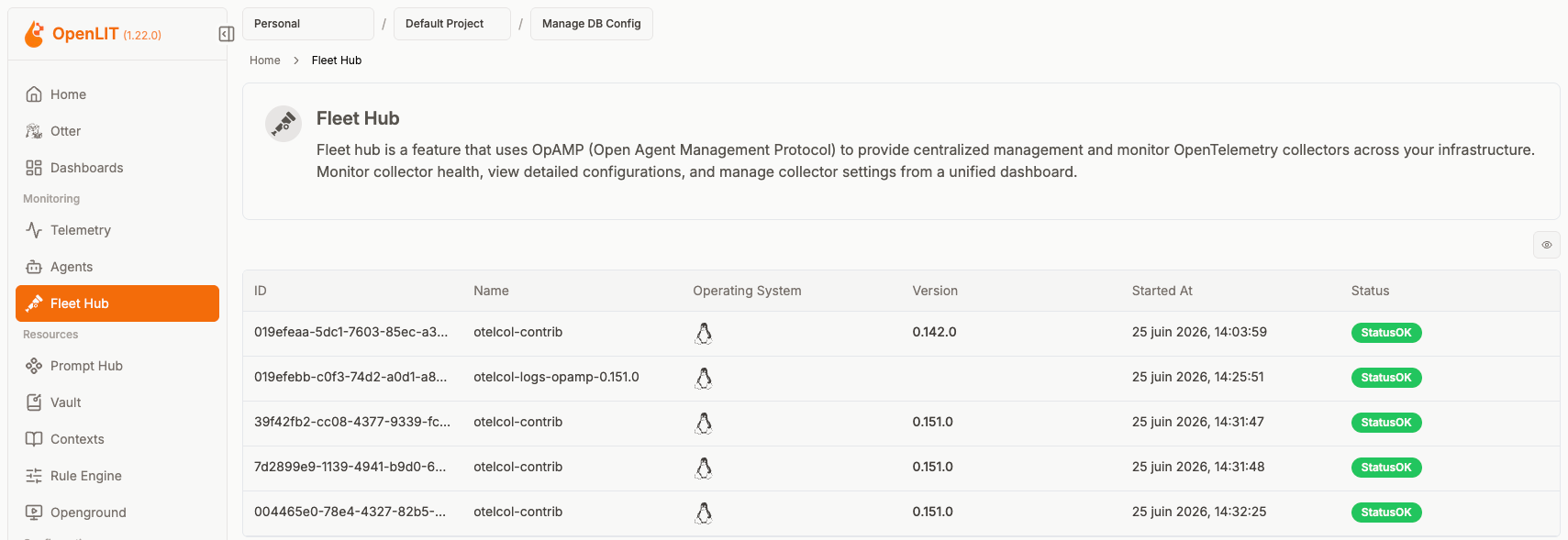
Elastic: Fleet existe, mais l’histoire OpenTelemetry est subtile
Elastic a déjà une notion de Fleet très mature dans son univers. Elastic Agent, Fleet Server, policies, intégrations: le modèle est connu.
Ce qui m’intéressait ici, c’était la partie OpenTelemetry Collector. Elastic documente l’ajout d’un OTel Collector dans Fleet. Cela montre une volonté d’intégrer OpenTelemetry dans un environnement de gestion existant.
Mais il faut faire attention à la lecture. Fleet chez Elastic n’est pas simplement synonyme d’OpAMP. Elastic a son propre modèle historique de management. L’intégration OpenTelemetry peut répondre à un besoin très réel sans pour autant signifier que toute la boucle de contrôle repose sur OpAMP.
C’est exactement le genre de nuance qu’il faut garder quand on benchmarke des solutions: le mot Fleet est là, l’expérience utilisateur est là, mais le protocole de contrôle et le niveau de standardisation ne sont pas toujours les mêmes.
Grafana: l’architecture compte autant que l’interface
Grafana Cloud documente également une offre de Fleet Management. Là encore, le sujet dépasse la simple génération de configuration.
Ce qui m’intéresse dans la documentation Grafana, c’est l’architecture. Quand un vendor explique comment il connecte les agents, comment il modélise les flottes et comment il sécurise la communication, on commence à avoir de quoi raisonner.
Un beau bouton “deploy” n’est pas suffisant. Dans un SI réel, on doit répondre à des questions moins glamour.
Qui a poussé cette configuration ? Sur quel périmètre ? Avec quelle validation ? Comment on fait un rollback ? Quelle est la source de vérité ? Est-ce que l’agent peut continuer à fonctionner si le plan de contrôle est indisponible ? Où sont stockés les secrets ? Comment on limite les droits du plan de contrôle ?
C’est là que le fleet management devient un vrai sujet d’architecture.
Apica: une autre lecture de la flotte
Apica documente aussi une approche Fleet Management dans son écosystème d’observabilité.
Là encore, on voit que le besoin est identifié: gérer des agents et des collectors à distance, organiser les configurations, donner une visibilité sur ce qui est déployé.
Ce qui me semble important, c’est que plusieurs acteurs convergent vers le même problème sans forcément converger immédiatement vers la même implémentation. C’est typique d’un marché qui sait qu’un irritant existe mais qui n’a pas encore stabilisé son standard opérationnel.
Pour un client, cela signifie qu’il ne suffit pas de demander “avez-vous du fleet management ?”. Il faut demander: quel agent, quel protocole, quelle architecture, quelle expérience et quel outillage pour mes équipes plateforme ?
Dynatrace et Bindplane: le signal d’acquisition
L’acquisition de Bindplane par Dynatrace est probablement l’un des signaux les plus forts.
Dynatrace a déjà son propre agent et son propre univers de monitoring. Acheter Bindplane, c’est reconnaître que le monde OpenTelemetry et la gestion de collectors hétérogènes deviennent stratégiques.
On peut y lire plusieurs choses.
D’abord, les clients veulent garder une part d’ouverture. Ils ne veulent pas forcément que toute la télémétrie passe par un agent unique propriétaire.
Ensuite, les grands comptes ont déjà des parcs hétérogènes. Même quand un vendor est très présent, il doit composer avec des équipes, des clouds, des clusters et des héritages différents.
Enfin, la bataille ne se joue pas seulement sur la collecte. Elle se joue sur le plan de contrôle.
Celui qui aide à gérer la flotte devient celui qui voit l’inventaire, pousse les configurations, structure les routes de données et influence les choix d’architecture.
L’inventaire des catégories
Après ce tour, je classerais les acteurs en plusieurs catégories.
Première catégorie: les produits qui documentent explicitement une relation avec OpAMP ou une gestion d’OpenTelemetry Collector proche du protocole. Bindplane est l’exemple principal.
Deuxième catégorie: les plateformes qui proposent une expérience de fleet management pour leurs agents ou collecteurs, avec une intégration OpenTelemetry plus ou moins ouverte. Elastic et Grafana entrent dans cette zone selon les usages.
Troisième catégorie: les solutions qui répondent au besoin de visibilité ou de configuration, mais où le mot fleet management peut recouvrir une expérience plus limitée ou plus propriétaire.
Quatrième catégorie: les démos, prototypes et implémentations communautaires qui prouvent que le protocole est exploitable, mais qui ne sont pas forcément des produits enterprise prêts à porter la responsabilité d’un grand parc.
Cette classification est plus utile qu’une liste de logos. Elle permet de poser les bonnes questions avant de choisir.
Pourquoi les grands comptes achètent autre chose qu’un protocole
J’ai eu en tête un cas client énergie, avec un appel d’offres autour de quinze millions d’euros.
À cette échelle, personne n’achète un protocole parce qu’il est élégant. Les équipes achètent une réduction de risque.
Elles veulent savoir comment déployer sans casser la production. Comment séparer les responsabilités entre l’équipe observabilité, les équipes plateforme, les équipes sécurité, les exploitants et les applicatifs. Comment tracer les changements. Comment prouver qu’une configuration a été appliquée. Comment limiter les blast radius. Comment gérer les exceptions.
Le protocole est important, mais il n’est qu’une partie de la réponse.
La vraie valeur d’une solution de fleet management, c’est la capacité à rendre ces opérations gouvernables.
Les questions RACI qui font mal
Quand on parle de fleet management, les questions RACI arrivent vite.
Qui possède la configuration par défaut ?
Qui valide les pipelines de télémétrie ?
Qui peut activer un receiver sensible ?
Qui autorise l’export vers une nouvelle destination ?
Qui porte le coût d’ingestion si une équipe active trop de logs ?
Qui intervient quand un collector commence à dropper des données ?
Qui décide du rollback ?
Qui audite les changements ?
Qui révoque les secrets générés ou réutilisés ?
Ces questions paraissent administratives, mais elles décident de l’adoption. Une solution qui ignore ces frictions peut être techniquement bonne et politiquement impossible à déployer.
Ce que les clients achètent vraiment
Les clients n’achètent pas seulement “OpAMP”. Ils achètent une manière de rendre l’observabilité opérable à l’échelle.
Ils achètent une console pour voir.
Ils achètent une API pour automatiser.
Ils achètent un modèle de permissions.
Ils achètent une histoire de rollback.
Ils achètent une intégration avec leurs pratiques GitOps, ITSM ou sécurité.
Ils achètent aussi une capacité à expliquer le système à des équipes qui ne vivent pas dans OpenTelemetry tous les jours.
C’est là que l’écart se creuse entre une bonne brique technique et une bonne offre enterprise.
Là où OpAMP devient intéressant
OpAMP devient intéressant quand il permet d’éviter deux impasses.
La première impasse, c’est le tout propriétaire. Chaque vendor gère son agent à sa façon, avec son backend, son format, ses règles, et le client perd la capacité à raisonner sur un modèle commun.
La deuxième impasse, c’est le bricolage local. Chaque équipe déploie son collector avec ses fichiers YAML, ses conventions et ses scripts. À petite échelle, ça fonctionne. À grande échelle, ça devient une dette opérationnelle.
Un protocole standard peut créer un langage commun entre agents, collectors, plans de contrôle et plateformes internes.
Mais pour que cette promesse tienne, il faut des implémentations solides, des outils d’administration, des modèles de sécurité et des retours terrain.

Pourquoi j’ai fait ce lab
J’ai lancé ce lab parce que je voyais beaucoup de conversations sur OpenTelemetry, mais peu de discussions concrètes sur le contrôle des agents.
Tout le monde veut des traces, des métriques et des logs. Peu de monde veut regarder en face la question de la flotte qui les produit.
Pourtant, c’est souvent là que les projets d’observabilité se bloquent. Pas dans la théorie. Dans les détails: packaging, configuration, secrets, permissions, rollback, inventaire, versionning, support, coût, ownership.
Je voulais donc sortir du débat abstrait et regarder qui documente quoi.
Le mauvais benchmark
Le mauvais benchmark serait de demander: quel produit a la meilleure UI ?
La UI compte, évidemment. Une interface claire réduit la friction. Bindplane, par exemple, donne une impression très forte de produit pensé pour l’usage.
Mais le vrai benchmark doit descendre plus bas.
Il faut regarder le modèle de contrôle, les protocoles, la persistance de configuration, les garanties, les modes dégradés, l’intégration CI/CD, la sécurité, l’audit et la capacité à vivre dans un SI qui n’est jamais propre.
Il faut aussi regarder ce qui est documenté publiquement. Une promesse commerciale sans documentation exploitable n’a pas le même poids qu’un guide d’intégration détaillé.
Mon point de départ
Mon point de départ est simple: OpAMP est une pièce importante, mais pas une baguette magique.
Le marché est encore en train de stabiliser la manière de gérer des agents OpenTelemetry à grande échelle. Certains acteurs avancent vite. D’autres ont déjà des systèmes propriétaires robustes. D’autres documentent des briques prometteuses.
Pour choisir, il faut éviter deux réflexes.
Le premier réflexe serait de croire qu’un standard suffit.
Le deuxième serait de croire qu’une console suffit.
Il faut les deux, plus l’architecture opérationnelle autour.
Sources
- Dynatrace to Acquire Bindplane
- Dynatrace Bindplane Hub
- Bindplane OpAMP documentation
- OpenLIT Fleet Hub documentation
- Elastic: Add an OTel Collector in Fleet
- OpenTelemetry Collector contrib OpAMP extension
- Apica: Fleet Management in OpenTelemetry
- Apica Fleet Management overview
- Grafana Fleet Management
- Grafana Fleet Management architecture
- OpAMP specification